

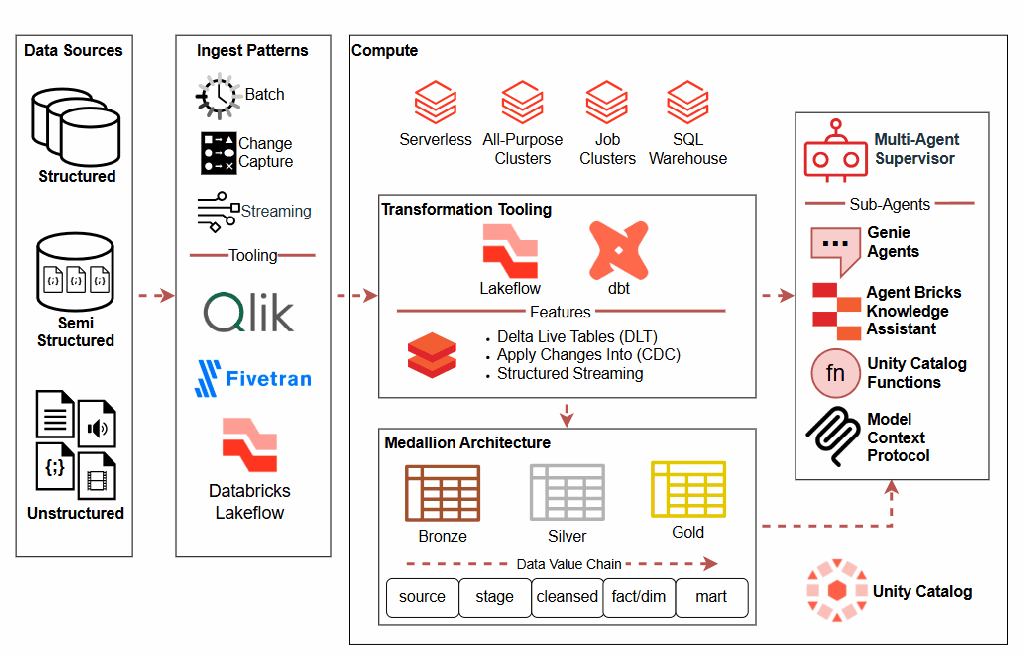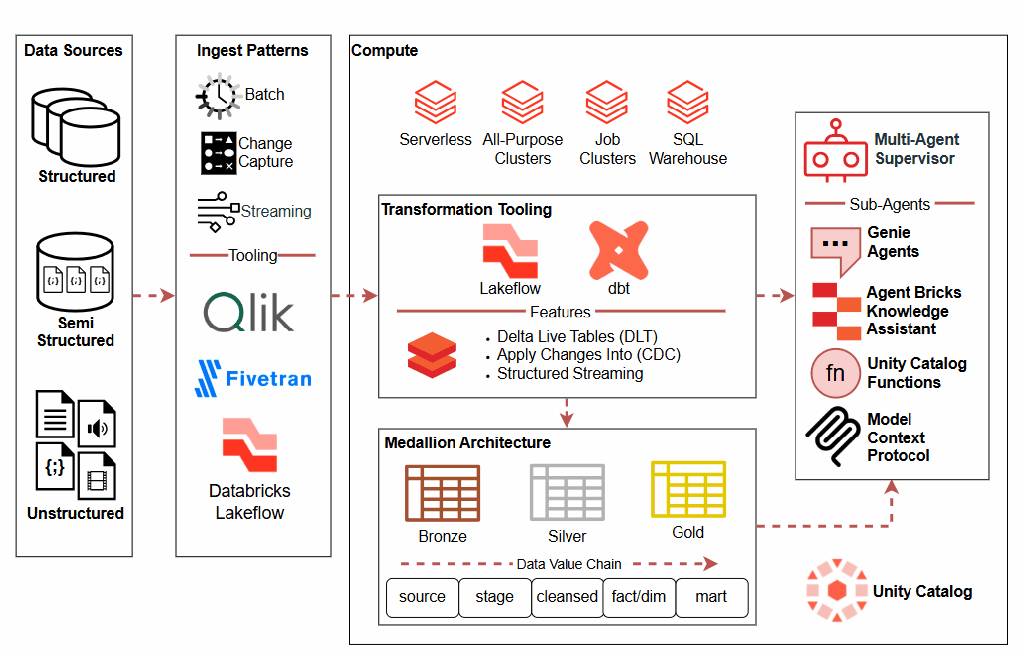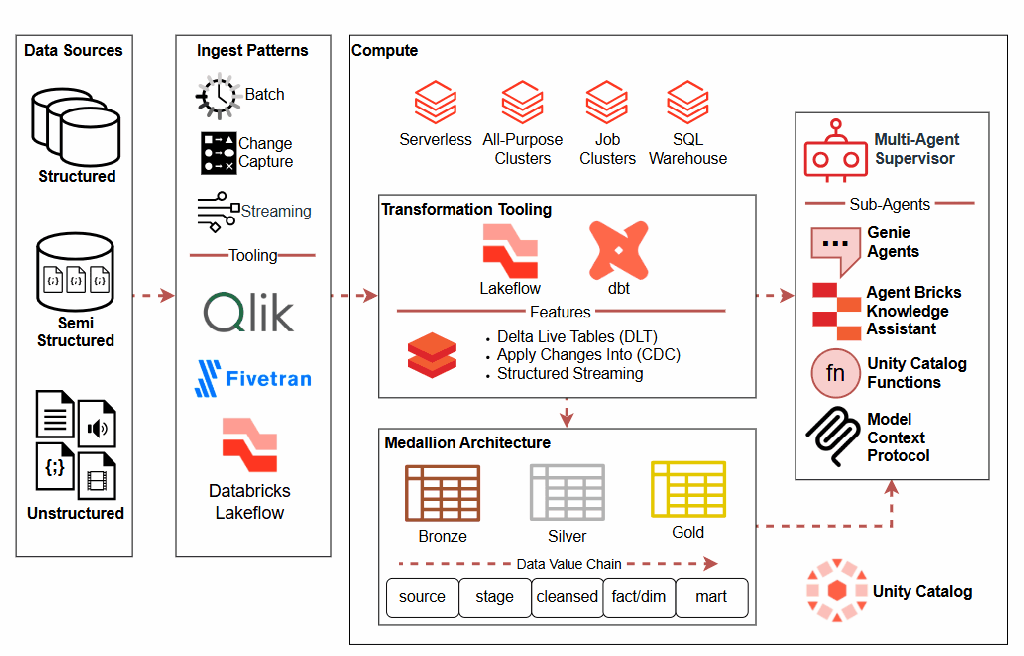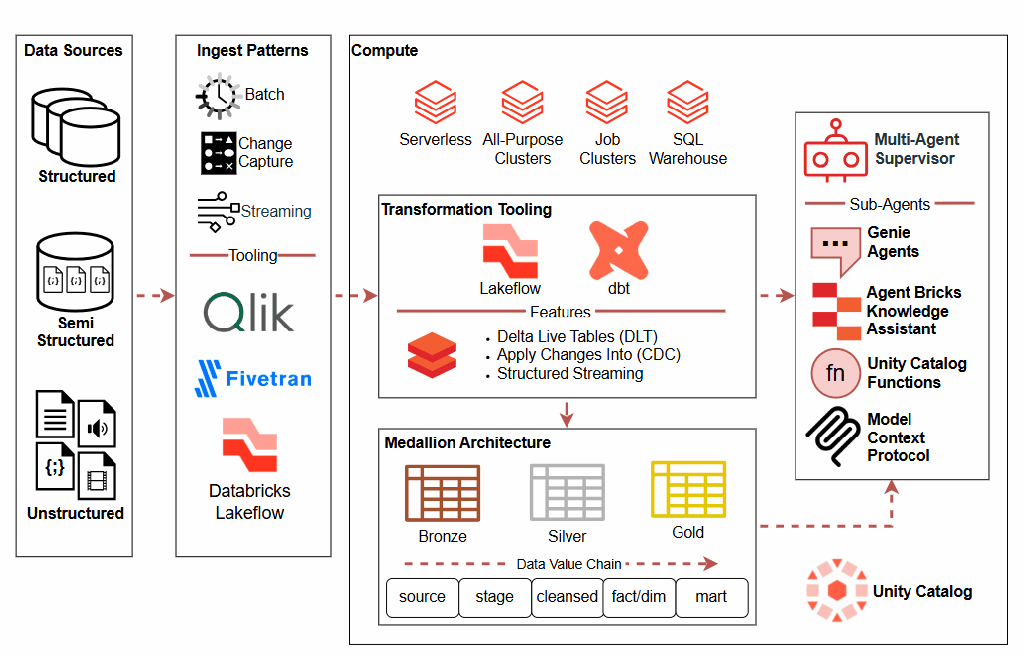
In today’s data-driven landscape, organizations rely on complex systems and integrations to process, transform, and deliver critical information. When something goes wrong, and it will. Having a robust observability is the difference between hours of frustrated debugging and quickly identifying and resolving issues. Observability rests on three foundational pillars that work together to provide complete visibility into your systems: metrics, traces, and logs. Each pillar serves a distinct purpose, and together they create a comprehensive framework for understanding the health and performance of your infrastructure.

Metrics serve as your early warning system, answering the crucial question: what went wrong? These quantitative measurements like response times, volume anomalies, system usage, or success rates act as vital signs for your data ecosystem. When a metric crosses a threshold or exhibits unusual patterns, it immediately alerts teams that something requires attention. Metrics provide the high-level view that helps you quickly assess whether systems are working as expected, whether quality is degrading, or whether performance is suffering. They’re your first line of defense, offering the bird’s-eye perspective needed to triage issues before they cascade into larger problems.
Once metrics identify an issue, traces help you pinpoint where it occurred by mapping the journey through your systems. Traces follow lineage across integrations, and system dependencies, creating a visual map of how well business applications are operating. This pillar is invaluable for understanding complex, distributed systems where a single element might touch dozens of services. When a metric signals a problem, traces quickly narrow down which specific component or integration point is the culprit.
Finally, logs provide the granular detail that explains why the issue happened. These detailed records capture events, errors, and contextual information at multiple viewpoints. Logs are where you find the stack traces, error messages, and specific conditions that caused a failure. Together, these three pillars create a complete observability framework where metrics tell you there’s a problem, traces show you where to look, and logs explain what you need to fix.
Grafana
The Grafana observability stack provides an integrated, open-source platform for collecting, storing, and analyzing telemetry data across distributed systems. The architecture separates concerns into specialized components, each optimized for specific data types and query patterns while maintaining interoperability through common protocols and APIs.
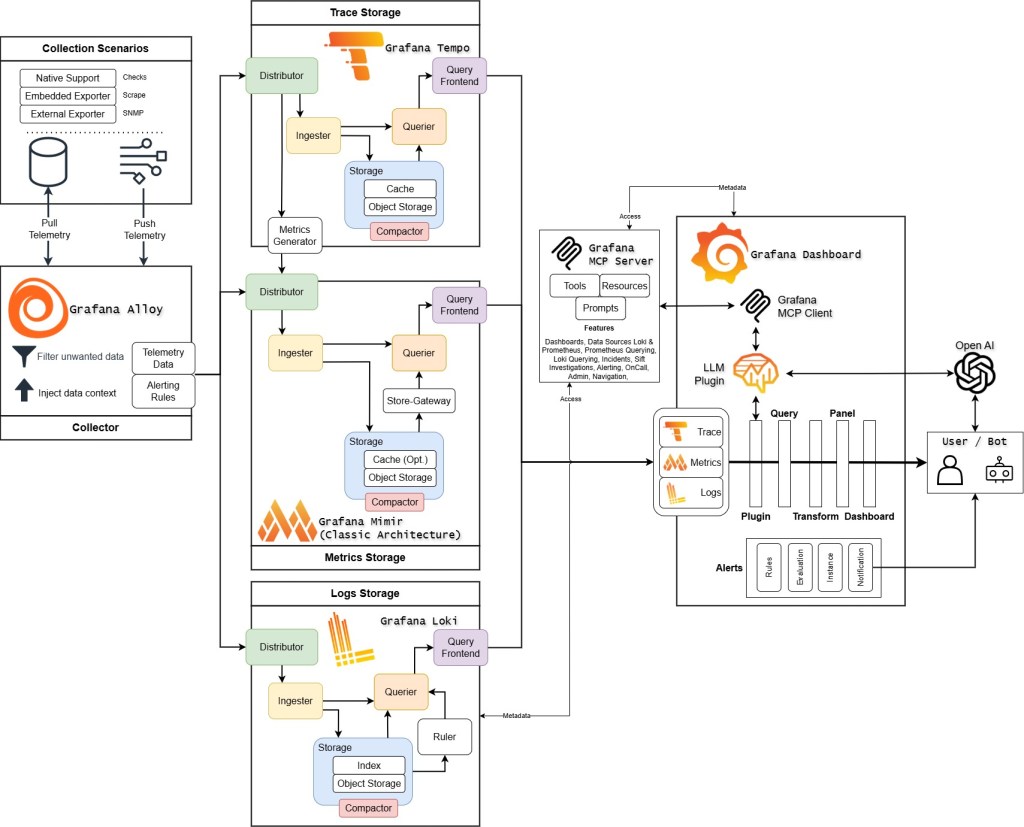
Alloy: Unified Telemetry Collection
Grafana Alloy serves as the telemetry collection layer, replacing the previous generation of agents (Grafana Agent, Prometheus Agent). Built on OpenTelemetry foundations, Alloy provides a vendor-neutral ingestion pipeline that can receive, process, and forward metrics, logs, traces, and profiles. It operates as a lightweight agent deployable as a sidecar, DaemonSet, or standalone collector, and supports dynamic configuration through a declarative pipeline language. Alloy handles protocol translation, data enrichment, filtering, and routing, allowing teams to normalize heterogeneous telemetry sources before they reach storage backends. Its component-based architecture enables flexible data transformation pipelines while maintaining low resource overhead, making it suitable for high-cardinality environments.
Tempo: Distributed Tracing at Scale
Tempo is a horizontally scalable, cost-efficient distributed tracing backend that stores trace data in object storage (S3, GCS, Azure Blob) rather than requiring expensive indexing infrastructure. Unlike traditional tracing systems that index all span attributes, Tempo uses a minimal indexing strategy by only indexing trace IDs by default which dramatically reduces storage and operational costs. It natively supports multiple ingestion formats including Jaeger, Zipkin, and OpenTelemetry Protocol (OTLP). Tempo’s architecture separates the write path (distributors and ingesters) from the read path (queriers), enabling independent scaling. The TraceQL query language provides powerful trace search and filtering capabilities based on span attributes, duration, and structure without requiring pre-defined indexes. Tempo integrates deeply with Grafana’s exemplars feature, linking metrics to traces for seamless correlation between aggregated metrics and detailed trace data.
Mimir: Horizontally Scalable Metrics
Grafana Mimir is a long-term storage solution for metrics, designed for massive scale and multi-tenancy. It implements the Prometheus remote write API and PromQL query engine while adding horizontal scalability through a microservices architecture with components for ingestion (distributors, ingesters), query (queriers, query-frontend), and compaction. Mimir stores data in object storage with a block-based format inherited from Prometheus TSDB. The query-frontend provides intelligent query splitting and caching, significantly improving query performance for large time ranges. Mimir’s architecture enables independent scaling of read and write paths, making it suitable for environments with thousands of Prometheus instances and petabytes of metrics data. Grafana Mimir: A Technical Architecture Overview – Ross McNeely
Loki: Log Aggregation Without Full-Text Indexing
Loki takes a fundamentally different approach to log aggregation compared to traditional solutions like Elasticsearch. Instead of indexing log contents, Loki only indexes metadata labels (similar to Prometheus labels), storing log lines as compressed chunks in object storage. This design choice dramatically reduces storage and operational costs while maintaining fast queries for labeled log streams. LogQL, Loki’s query language, supports grep-like filtering, pattern extraction, and metric aggregation from logs. Loki’s architecture mirrors Prometheus with distributors, ingesters, and queriers, enabling horizontal scalability. The key insight is that most log queries filter by metadata (service, pod, namespace) before searching content, making full-text indexing unnecessary for many use cases. Loki supports structured metadata extraction and log-to-metrics conversion, allowing teams to derive metrics from log data without maintaining separate instrumentation. A Grafana Loki Overview – Ross McNeely
Grafana Dashboards: Unified Visualization and Correlation
Grafana provides the query and visualization layer that unifies data from Tempo, Mimir, Loki, and other data sources. Its dashboard system supports mixed data sources within single visualizations, enabling correlation between metrics, logs, and traces. Grafana’s data links and exemplars create navigable connections. Clicking a metric spike can jump directly to related logs or traces. The Explore interface provides ad-hoc query capabilities optimized for each data source type, with specialized UI for building PromQL, LogQL, and TraceQL queries. Grafana supports alerting based on queries against any connected data source, with alert rules evaluated by a separate Grafana Alertmanager-compatible engine. Templating and variables enable dynamic, reusable dashboards that adapt to different environments and services. The plugin architecture allows extension through custom panels, data sources, and applications, while the RBAC system enables fine-grained access control for enterprise deployments.
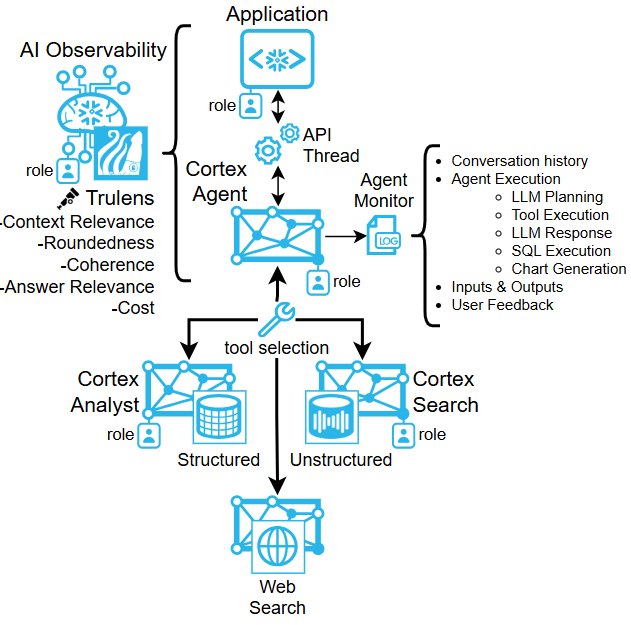
Grafana MCP Integration: Model Context Protocol
Grafana’s Model Context Protocol implementation enables AI agents and Large Language Models to interact directly with observability data through standardized interfaces. The MCP server exposes Grafana’s data sources, dashboards, and query capabilities as structured resources and tools that AI systems can discover and utilize. This allows LLMs to execute PromQL, LogQL queries, retrieve dashboard configurations, analyze time-series data, and correlate signals across metrics, logs, and traces without custom integrations. The protocol handles authentication, rate limiting, and query validation while maintaining the security boundaries of Grafana’s existing RBAC system. MCP enables use cases like natural language querying of observability data, automated incident analysis, intelligent alert triage, and AI-assisted dashboard creation. By standardizing how AI systems access observability telemetry, MCP positions Grafana as a first-class data source for AI-powered operational workflows, allowing teams to leverage LLMs for root cause analysis, anomaly explanation, and predictive insights without building custom API wrappers or data export pipelines.
The Grafana stack’s power lies in its cohesive design: shared label conventions between Mimir and Loki enable correlated queries, exemplars link metrics to traces, and Alloy ensures consistent metadata enrichment across all telemetry types. This creates a unified observability platform where context flows naturally between different telemetry signals.

Leave a comment