
Artificial Intelligence transforms how we solve complex problems, make decisions, and extract insights from data. However, there’s a fundamental truth that often gets overlooked in the excitement of deploying the latest AI models: the quality of your AI solution is fundamentally limited by the quality of your data.
Poor data quality doesn’t just reduce AI performance, it can lead to biased decisions, regulatory violations, customer dissatisfaction, and costly business mistakes. The old adage “garbage in, garbage out” has never been more relevant than in the age of AI.
This is where data quality metrics become essential. By measuring and improving the eight core dimensions of data quality: accuracy, completeness, consistency, integrity, reasonability, timeliness, uniqueness, and validity an organization can build AI solutions that are reliable, trustworthy, and valuable.
Quick Overview of the Eight Data Quality Pillars
- Accuracy: Data correctly represents the real-world values or facts it is intended to describe.
- Completeness: All required data fields and records are present without missing values or gaps.
- Consistency: Data values and formats remain uniform across different systems, datasets, and time periods.
- Integrity: Data maintains proper relationships and constraints between related fields and tables.
- Reasonability: Data values fall within expected ranges and make logical sense given the context.
- Timeliness: Data is available when needed and reflects the most current information for its intended use.
- Uniqueness: Each data record appears only once without unwanted duplicates in the dataset.
- Validity: Data conforms to defined formats, standards, and business rules for its specific field or domain.
The Eight Pillars of Data Quality for AI

1. Accuracy: Getting the Facts Right
How well data reflects the true, real-world values it’s supposed to represent. Inaccurate training data teaches AI models incorrect patterns, leading to poor predictions and unreliable outcomes. A customer recommendation system trained on incorrect purchase histories will make irrelevant suggestions, damaging user experience and business results.
Implementation examples:
- Frontend: Implement real-time validation rules at data entry points
- Backend: Use statistical outlier detection to identify potentially incorrect values
2. Completeness: Filling the Information Gaps
The extent to which required data elements are present and populated. Missing data can introduce bias and reduce model performance. If customer demographic information is systematically missing for certain groups, AI models may perform poorly for those populations, creating fairness and effectiveness issues.
Implementation examples:
- Frontend: Implement intelligent imputation strategies for missing values
- Backend: Track percentage of null values across critical fields
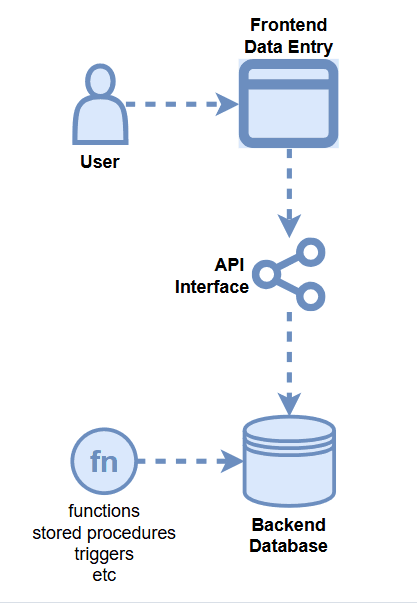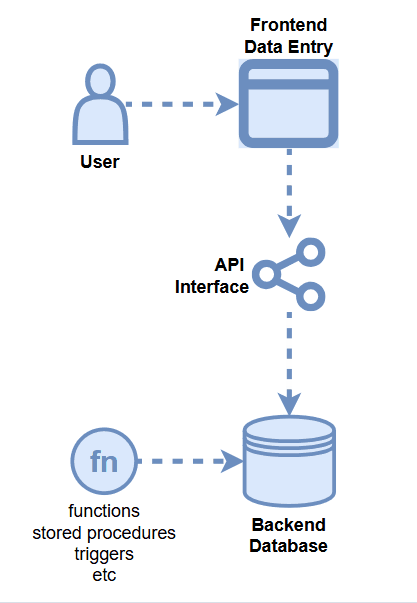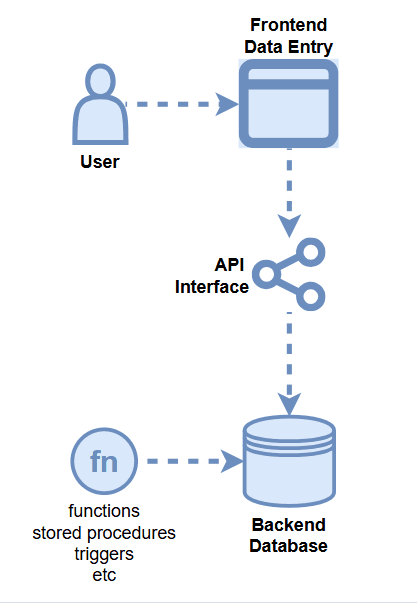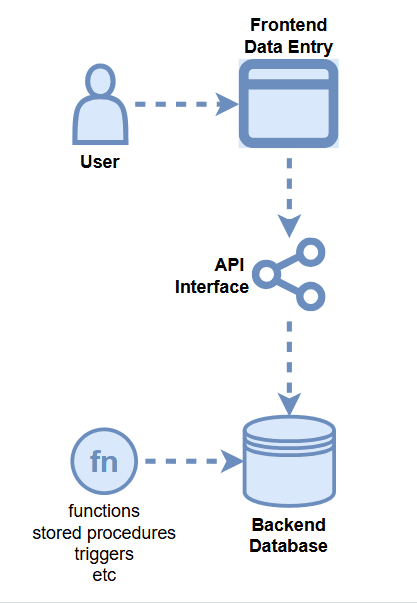
Data Quality Opportunities
- Frontend Application Logic
- API Logic
- Backend Database DDL
- Backend Database Logic
3. Consistency: Maintaining Uniformity Across Systems
Whether data is uniform and standardized across different systems, formats, and time periods. Inconsistent data formats confuse AI models and reduce their ability to learn meaningful patterns. When customer names are stored as “John Smith” in one system and “Smith, John” in another, the AI may treat them as different entities.
Implementation examples:
- Frontend: Validate data entry values.
- Backend: Standardize date formats across all data sources
4. Integrity: Preserving Data Relationships
Whether data maintains proper relationships and referential integrity across linked records and systems. Broken relationships in data can lead to incorrect correlations and flawed insights. If order records are disconnected from customer records, AI models cannot properly understand customer behavior patterns.
Implementation examples:
- Frontend: Manage the data state while entering transactions.
- Backend: Implement foreign key constraints in databases

Data Quality Opportunities
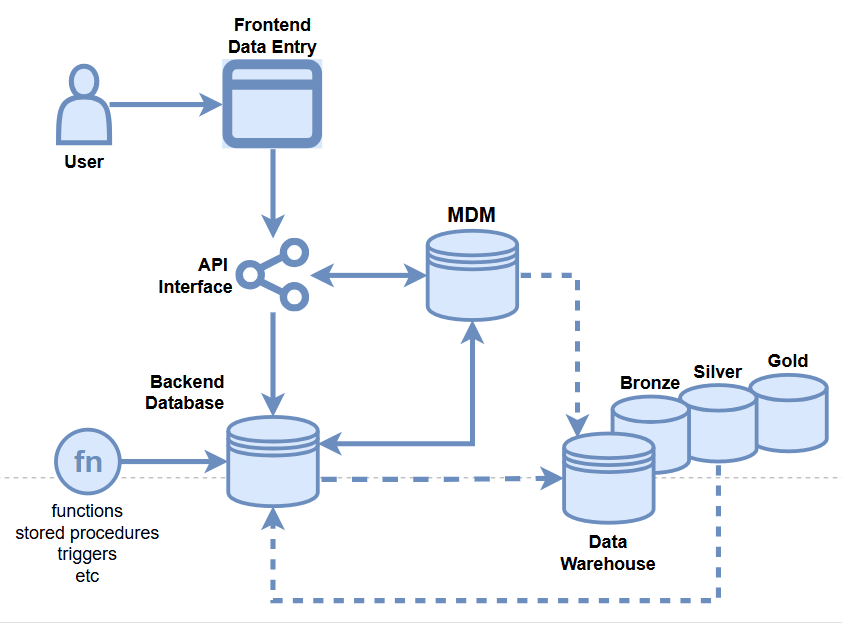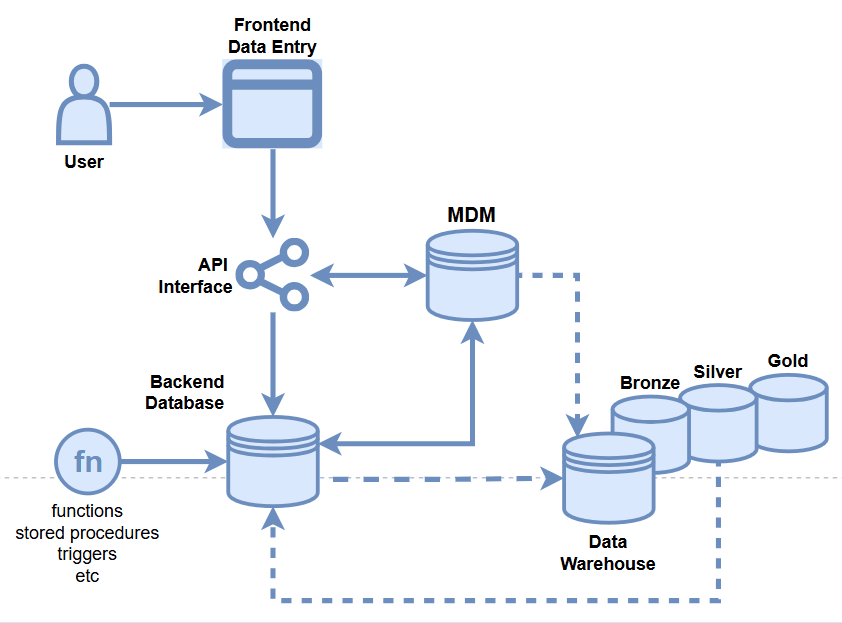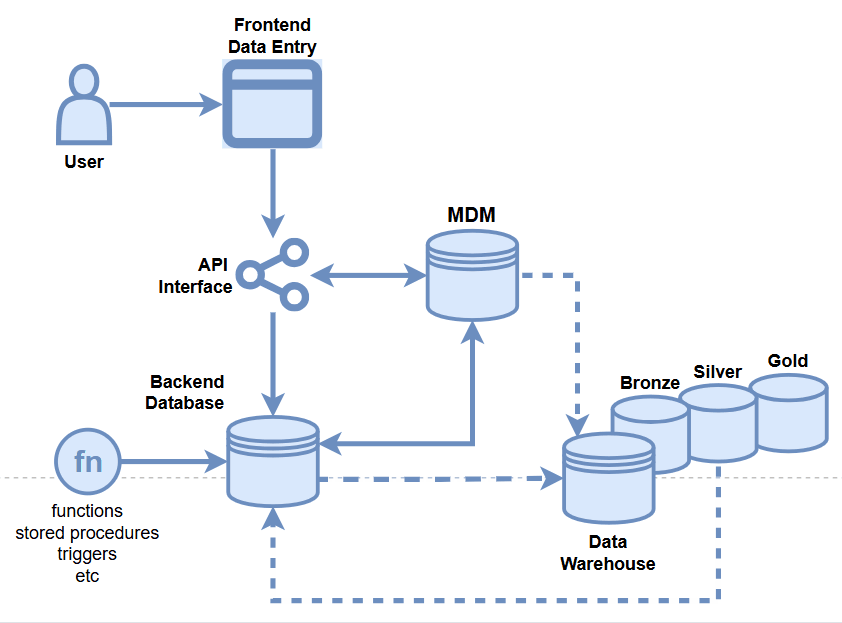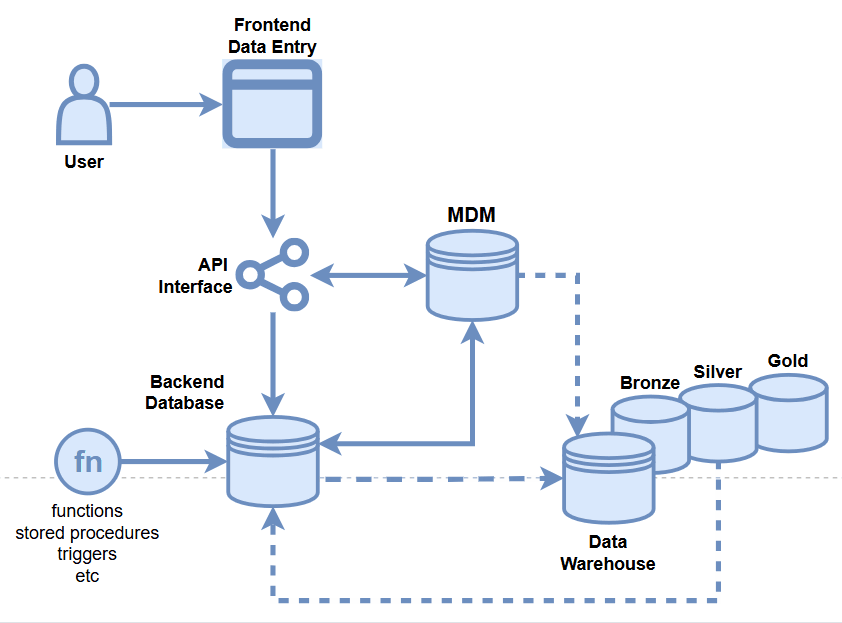
- Master Data Management
- API Integration
- Database Integration
- MDM Portal
- Data Owners
- Golden Record
- Etc.
5. Reasonability: Ensuring Logical Data Values
Whether data values fall within expected and logical ranges based on business rules and real-world constraints. Unreasonable data can skew model training and lead to nonsensical predictions. An AI model that encounters a customer age of 250 years or a negative sales amount needs robust reasonability checks to handle such anomalies appropriately.
Implementation examples:
- Frontend: Implement business rule validation engines.
- Backend: Use statistical methods to identify extreme outliers
6. Timeliness: Keeping Data Current and Relevant
Whether data is up-to-date and available when needed for decision-making. Stale data can make AI models irrelevant or counterproductive. A fraud detection system using month-old transaction patterns may miss emerging fraud techniques, while a demand forecasting model needs current market data to make accurate predictions.
Implementation examples:
- Monitor data freshness and update frequencies
- Implement real-time or near-real-time data pipelines
- Set data aging policies and archival rules
- Create timeliness dashboards for critical data feeds
7. Uniqueness: Eliminating Duplicate Records
The degree to which data records are free from inappropriate duplication. Duplicate records can bias AI models by overrepresenting certain patterns or entities. If the same customer appears multiple times in training data, the model may overfit to that customer’s behavior patterns, reducing its ability to generalize.
Implementation examples:
- Frontend: Implement fuzzy matching algorithms for duplicate detection
- Backend: Create unique identifiers for all entities
Data Quality Opportunities
- Master Data Management
- Data Warehouse
- Backend Database
8. Validity: Conforming to Defined Standards
Whether data conforms to defined formats, patterns, and business rules. Invalid data formats can cause AI processing errors or lead to misinterpretation. Email addresses without proper format validation, phone numbers with inconsistent formatting, or product codes that don’t follow established patterns can all compromise AI model performance.
Implementation examples:
- Frontend: Set logical range validations (ages between 0-120, prices above $0)
- Backend: Build comprehensive data validation frameworks
Data Quality Metrics in AI Projects
You do not need to start at an enterprise quality level. It can be implemented as part of an AI Project scoped to a limited data domain. Don’t let the scale of your data quality issues prevent a quality AI Solution. Before launching any AI initiative, conduct a comprehensive data quality assessment across all eight dimensions. This baseline measurement helps you understand current state and prioritize improvement efforts.
Establish Monitoring Systems
Implement automated monitoring that tracks data quality metrics continuously, not just during initial development. Data quality can degrade over time due to system changes, new data sources, or evolving business processes. Define acceptable levels for each data quality dimension based on your AI use case requirements. Critical applications like medical diagnosis or financial risk assessment may require higher quality thresholds than less sensitive applications.
Establish processes that feed data quality insights back into data collection and management systems. When AI models detect patterns that suggest data quality issues, this information should trigger investigations and corrections.
Invest in Data Governance
Strong data governance frameworks ensure consistent application of data quality standards across the organization. This includes clear ownership, standardized processes, and regular quality reviews. Organizations that prioritize data quality metrics in their AI initiatives see significant benefits:

The Business Impact of Quality-Driven AI
- Improved Model Performance: Higher quality data leads to more accurate predictions and better business outcomes.
- Reduced Bias and Fairness Issues: Systematic quality measurement helps identify and address bias in training data.
- Faster Time-to-Value: Quality data reduces the time spent on data cleaning and model debugging, accelerating AI project delivery.
- Greater Stakeholder Trust: Transparent quality metrics build confidence in AI-driven decisions among business users and customers.
- Regulatory Compliance: Many industries require explainable AI systems backed by high-quality data.
- Cost Reduction: Preventing data quality issues is significantly less expensive than fixing problems after AI models are deployed.
Moving Forward: Making Data Quality a Priority
The most sophisticated AI algorithms cannot overcome fundamental data quality problems. Organizations that treat data quality as an afterthought will struggle to realize the full potential of their AI investments.
Start by implementing measurement systems for the eight core data quality dimensions. Establish clear ownership and accountability for data quality. Invest in the tools, processes, and culture changes needed to maintain high-quality data over time.
Remember: in the world of AI, data quality isn’t just a technical requirement—it’s a business imperative. The organizations that master data quality metrics will build AI solutions that are not only technically sound but also trustworthy, fair, and valuable to their stakeholders.
Your AI models are only as good as the data they’re built on. Make that data the best it can be.



Leave a reply to The Data Detective: How Quality Assessment Shapes Successful Data and AI Project Scoping – Ross McNeely Cancel reply