
Overview of Metrics for Tracking AI Models
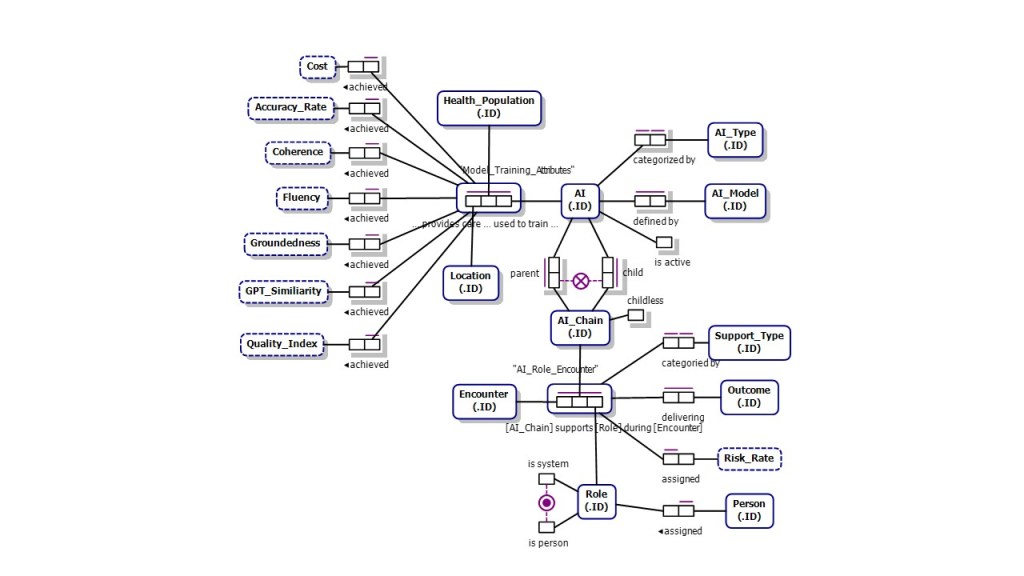
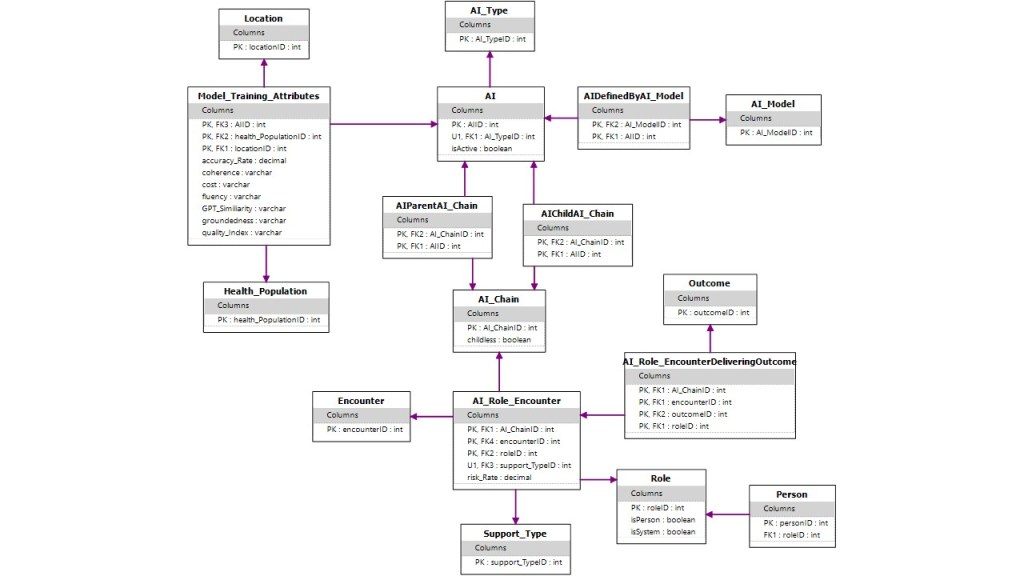
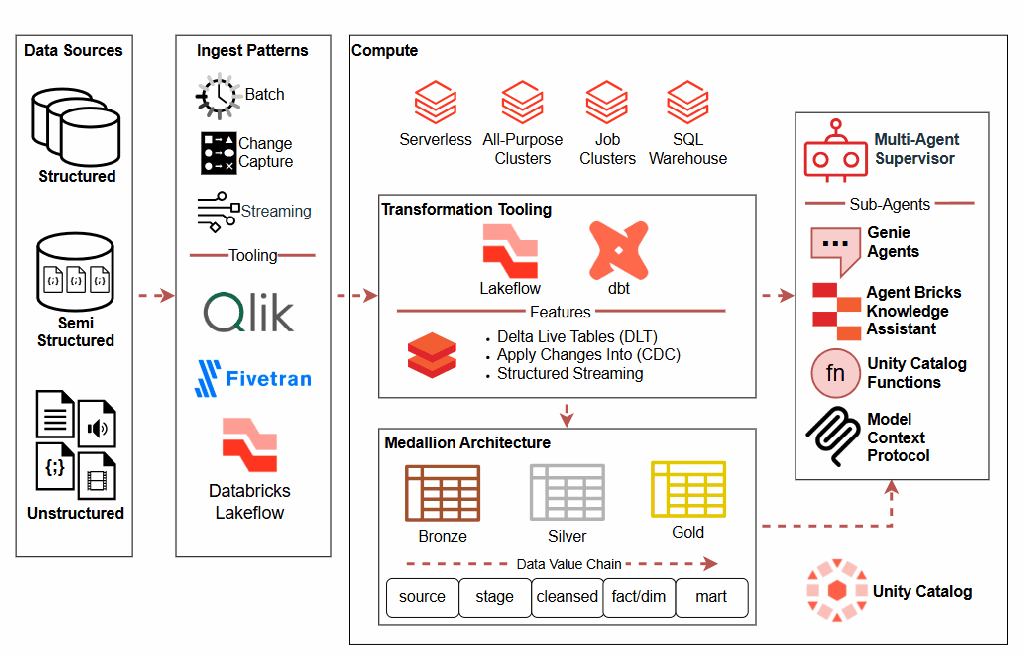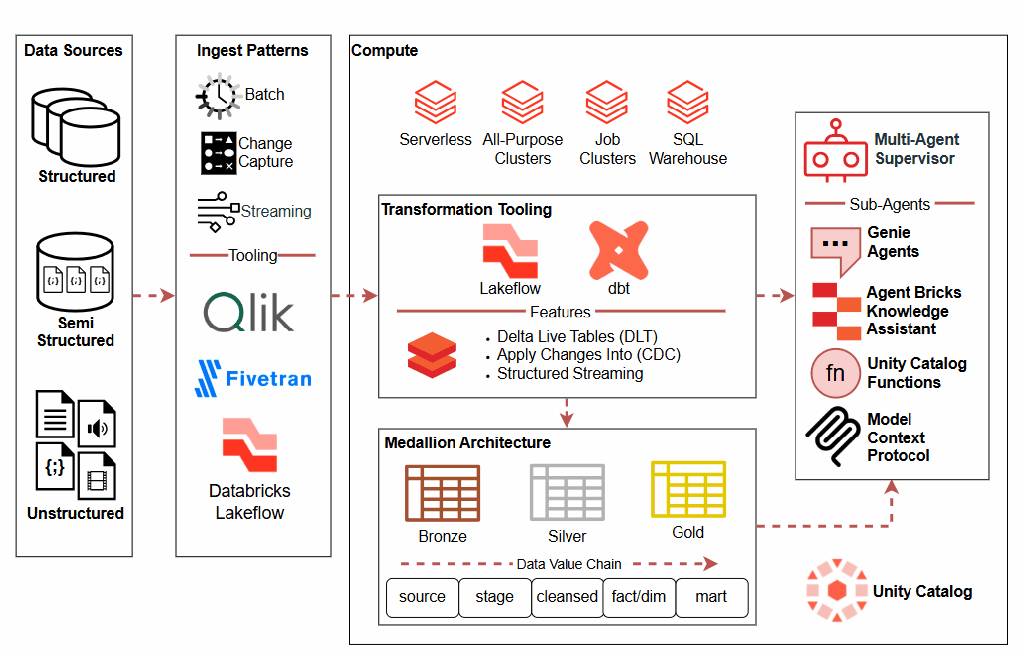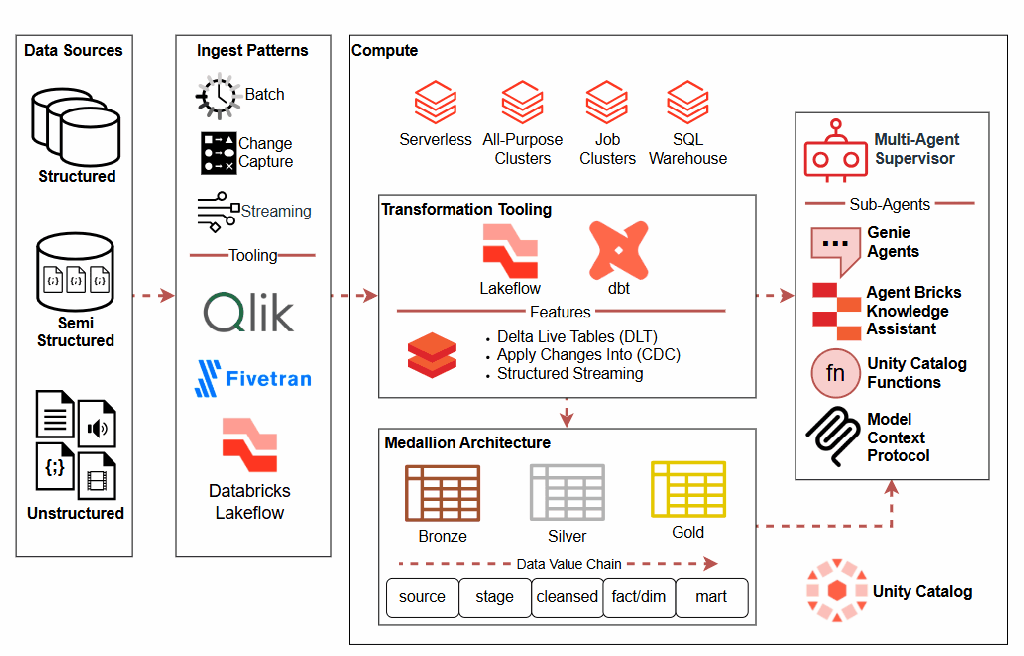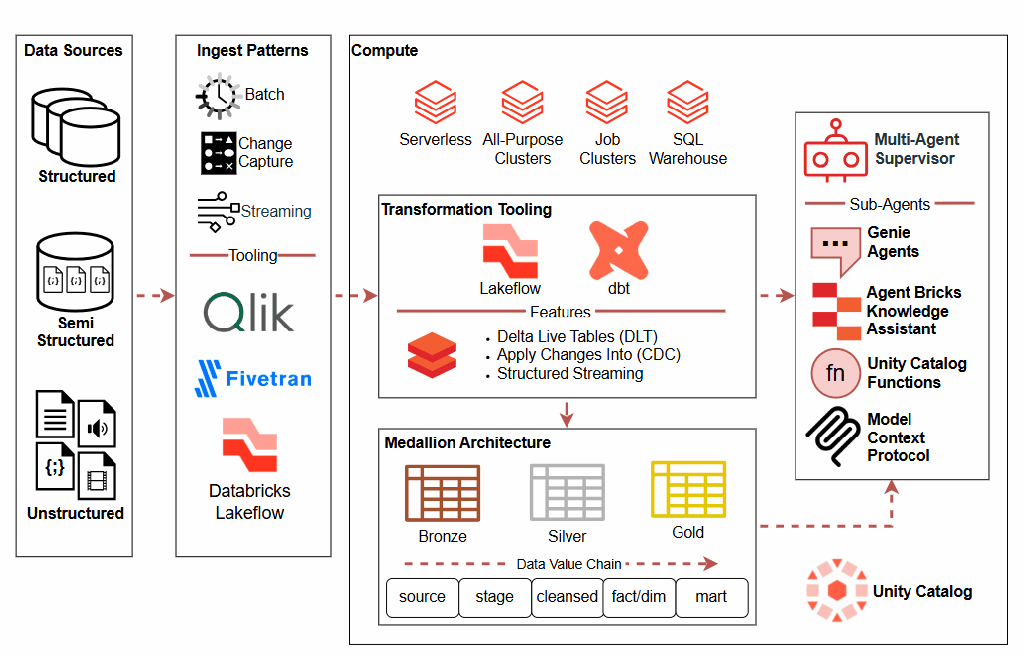
Full Diagrams: ORM, Barker, ERD at bottom of article.
Monitoring AI performance across diverse training locations and varied health populations is an increasingly critical aspect of ensuring the robustness and inclusivity of AI models. Training location can significantly influence the quality of datasets used, as geographical, cultural, and socio-economic factors impact the patterns and diversity of information captured. A model trained on data from a specific location might excel in scenarios pertinent to that region but fail to generalize effectively in others. By tracking these variables, stakeholders can identify biases and gaps, ensuring models are both geographically neutral and globally relevant.
Similarly, variations across health populations demand meticulous performance tracking. Health-related AI models often rely on data that represents different demographics, medical conditions, and treatment protocols. Without careful monitoring, these models risk underperforming or producing inaccurate results for underrepresented groups, exacerbating health disparities. Tracking such metrics helps guarantee equitable performance and promotes the ethical deployment of AI in sensitive areas like healthcare. Together, these efforts to monitor training location and health population metrics reinforce the pursuit of AI systems that are both fair and effective, tailored to a diverse and interconnected world.

Update on Key Metrics for Tracking AI Models
Evaluating AI models is a critical component in the development, deployment, and monitoring of artificial intelligence systems. To ensure that a model performs effectively and meets the desired standards, various metrics are used to assess its output. This document provides an overview of key metrics for tracking AI models: Accuracy, Coherence, Fluency, Groundedness, GPT Similarity, Quality Index, and Cost. These metrics collectively measure different aspects of an AI model’s performance, offering a comprehensive framework for evaluation.
Accuracy
Definition: Accuracy is a binary measure that assesses whether the model-generated text matches the correct answer according to the dataset.
Method: The result is quantified as 1 if the generated text exactly matches the correct answer, and 0 otherwise.
Purpose: This metric is particularly useful for tasks requiring precise answers, such as question-answering systems and factual data generation. While simple in calculation, it is highly effective in determining how well the model adheres to ground truth.
Coherence
Definition: Coherence measures the extent to which a model’s output flows smoothly, reads naturally, and resembles human-like language.
Assessment: Coherent text should exhibit logical structure and seamless progression of ideas, avoiding jarring or fragmented sentences.
Purpose: This metric ensures the generated text is not only syntactically correct but also narratively logical, making it suitable for applications like storytelling, chatbots, and content generation.
Fluency
Definition: Fluency evaluates how well the model-generated text adheres to grammatical rules, syntactic structures, and appropriate vocabulary usage.
Goal: Text with high fluency is linguistically correct and natural-sounding, ensuring clarity and professionalism.
Importance: Fluency plays a central role in determining the linguistic quality of outputs, especially in applications requiring high standards of readability and grammatical precision.
Groundedness
Definition: Groundedness measures the alignment between the model’s generated answers and the input data.
Method: A grounded response is one that relies on, and accurately reflects, the input context or dataset, rather than hallucinating information.
Application: This metric is crucial for ensuring reliability in domains such as healthcare, finance, and education, where accuracy and source fidelity are paramount.
GPT Similarity
Definition: GPT Similarity quantifies the semantic similarity between a ground truth sentence (or document) and the prediction sentence generated by an AI model.
Method: Using advanced algorithms, this metric compares the underlying meaning of the generated text with the reference text, even if the wording differs.
Significance: GPT Similarity is highly useful for tasks such as paraphrasing, summarization, and machine translation, where semantic integrity is more important than exact wording.
Quality Index
Definition: The Quality Index is a comparative aggregate score ranging from 0 to 1, with higher values indicating better performance.
Components: This index combines multiple metrics—such as Accuracy, Coherence, Fluency, Groundedness, and GPT Similarity—into a single measurable score.
Purpose: It serves as a holistic measure of a model’s overall quality, simplifying the comparison between different models and configurations.
Cost
Definition: Cost refers to the expense of using the AI model, typically calculated on a price-per-token basis.
Utility: This metric is essential for evaluating the economic efficiency of a model. By comparing cost with Quality Index, users can determine an appropriate tradeoff between performance and affordability.
Implications: Cost considerations are particularly relevant for scaling applications, where high-quality models may incur significant expenses for large datasets or frequent use.
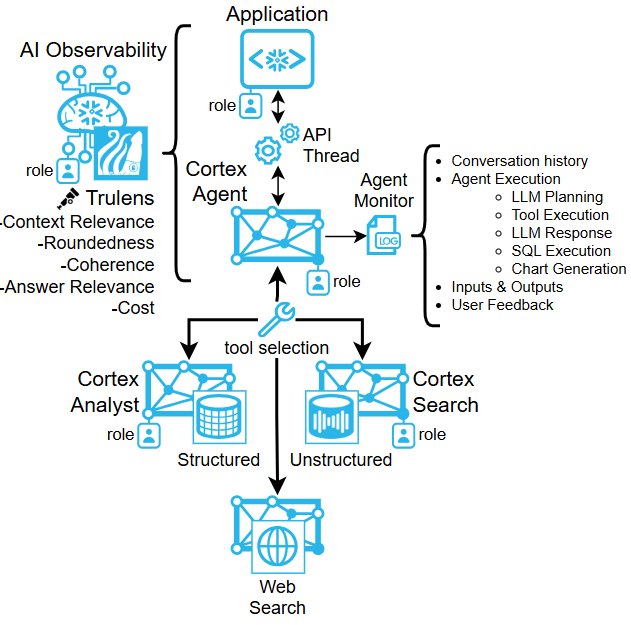
Tracking Multi-Agent Usage in Healthcare

In healthcare decision-making, tracking multi-agent hierarchies involves a nuanced approach to understanding the interplay between various stakeholders—clinicians, patients, administrators, and policymakers. Effective tracking requires robust systems that can capture the dynamics of shared authority, data flow, and accountability across these layers. By utilizing advanced data analytics and AI-driven insights, healthcare systems can map these interactions to optimize decision processes, ensuring that outcomes align with patient-centric care while balancing operational efficiency. This approach not only enhances transparency but also fosters collaboration among agents, enabling adaptive strategies tailored to complex and evolving healthcare needs.
Tracking and evaluating AI models using these core metrics provides a robust framework for optimizing performance. Each metric addresses a distinct aspect of the model’s capabilities, from ensuring factual accuracy to maintaining linguistic quality and managing operational costs. By leveraging these measures together, stakeholders can make informed decisions to balance quality and efficiency, tailoring AI solutions to meet specific requirements.
Full Healthcare AI Tracking Object-Role Model (to date)
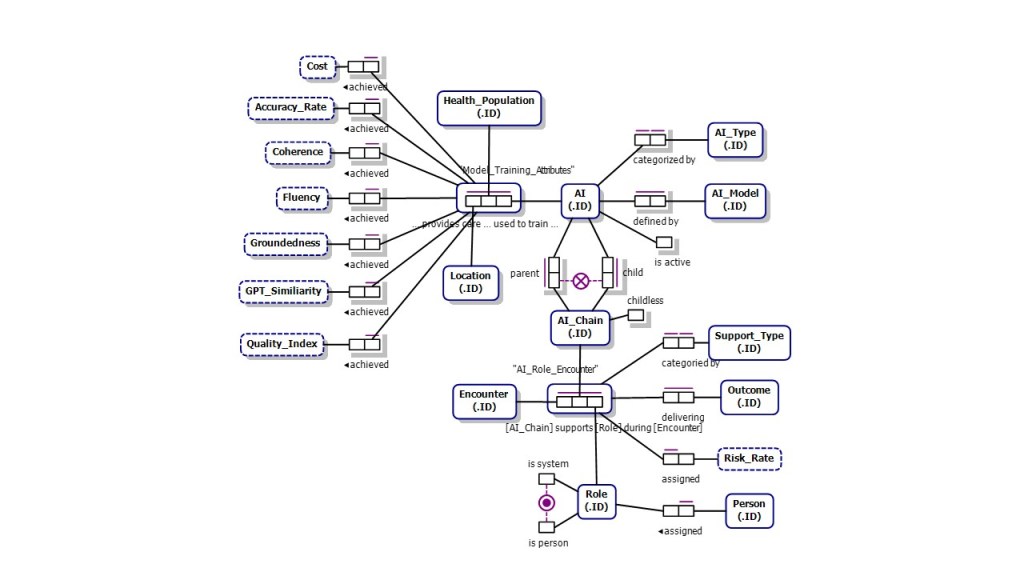
Full Healthcare AI Tracking Barker Model (to date)

Full Healthcare AI Tracking ERD Model (to date)

Leave a comment